本文根据prometheus master分支最新代码所写,commit id:dca84112a97ea7a31f2ddb2ce7cfb4f7cae91f86
告警是prometheus的一个重要功能,接下来从源码的角度来分析下告警的执行流程。
整体的大致流程请见下方流程图:
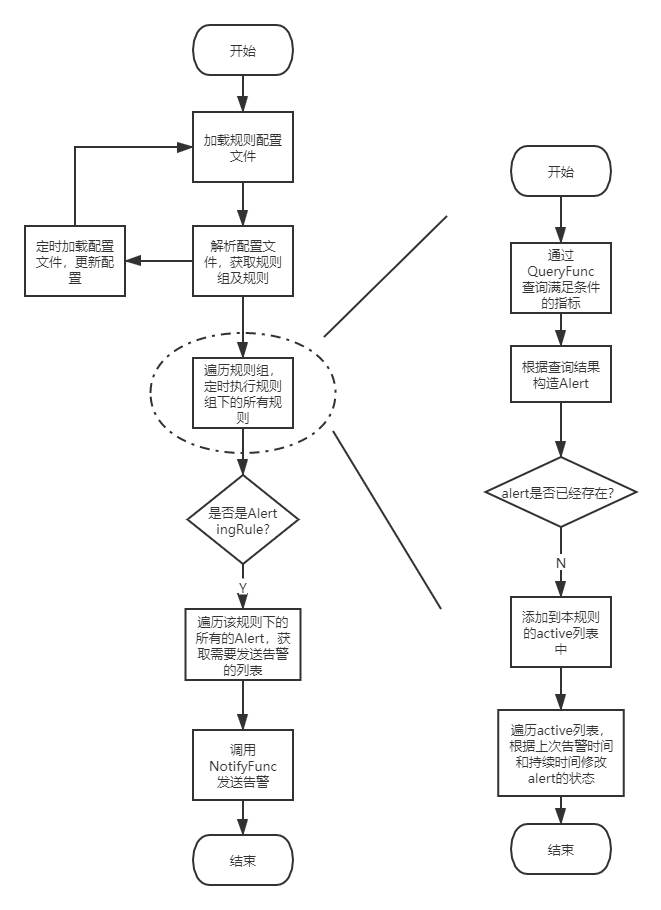
prometheus的告警部分的源码主要在github.com/prometheus/prometheus/rules文件夹下面,主要结构如下:
// The Manager manages recording and alerting rules.
type Manager struct {
opts *ManagerOptions // 初始化时的option
groups map[string]*Group // 规则group
mtx sync.RWMutex
block chan struct{} // 更新规则组后阻塞,直到storage准备好了后再执行
done chan struct{}
restored bool
logger log.Logger
}
Manager负责管理规则,定时扫描规则文件、加载新的规则、执行规则、发送告警信息等。首先是创建Manager:
var (
localStorage = &readyStorage{}
remoteStorage = remote.NewStorage(log.With(logger, "component", "remote"), prometheus.DefaultRegisterer, localStorage.StartTime, cfg.localStoragePath, time.Duration(cfg.RemoteFlushDeadline))
fanoutStorage = storage.NewFanout(logger, localStorage, remoteStorage)
)
ruleManager = rules.NewManager(&rules.ManagerOptions{
Appendable: fanoutStorage,
Queryable: localStorage,
QueryFunc: rules.EngineQueryFunc(queryEngine, fanoutStorage),
NotifyFunc: sendAlerts(notifierManager, cfg.web.ExternalURL.String()),
Context: ctxRule,
ExternalURL: cfg.web.ExternalURL,
Registerer: prometheus.DefaultRegisterer,
Logger: log.With(logger, "component", "rule manager"),
OutageTolerance: time.Duration(cfg.outageTolerance),
ForGracePeriod: time.Duration(cfg.forGracePeriod),
ResendDelay: time.Duration(cfg.resendDelay),
})
几个重要的配置:
- Appendable:负责临时存储满足告警规则的数据。
- Queryable:负责查询Appendable中存储的数据。
- QueryFunc:用于查询prometheus数据。
- NotifyFunc:用于满足告警条件时发送通知。
- OutageTolerance:?????
- ForGracePeriod:?????
- ResendDelay:发送告警通知后,在这段时间后不再重复发送通知。
一、读取规则配置
程序启动时会创建一系列的reloader,其中有一个是读取规则文件,更新Manager:
reloaders := []reloader{
// 此处省略其他reloader,感兴趣的可以自行查看源码............
{
name: "rules",
reloader: func(cfg *config.Config) error {
// Get all rule files matching the configuration paths.
var files []string
for _, pat := range cfg.RuleFiles {
fs, err := filepath.Glob(pat)
if err != nil {
// The only error can be a bad pattern.
return errors.Wrapf(err, "error retrieving rule files for %s", pat)
}
files = append(files, fs...)
}
return ruleManager.Update(
time.Duration(cfg.GlobalConfig.EvaluationInterval),
files,
cfg.GlobalConfig.ExternalLabels,
)
},
},
}
这里会依次读取配置文件中rule_files下的配置项,扫描满足条件的配置文件,然后更新规则。
详细代码如下:
func (m *Manager) Update(interval time.Duration, files []string, externalLabels labels.Labels) error {
m.mtx.Lock()
defer m.mtx.Unlock()
// 加载配置的规则组
groups, errs := m.LoadGroups(interval, externalLabels, files...)
if errs != nil {
for _, e := range errs {
level.Error(m.logger).Log("msg", "loading groups failed", "err", e)
}
return errors.New("error loading rules, previous rule set restored")
}
m.restored = true // 标记规则已经重新加载过了
var wg sync.WaitGroup
for _, newg := range groups {
// 判断文件配置中的规则是否已经存在,如果已经存在并且未经修改,就略过
// 否则,停止原来的规则并从当前规则组列表中删除,然后复制旧规则组的状态至同名的新的规则组
gn := groupKey(newg.file, newg.name)
oldg, ok := m.groups[gn]
delete(m.groups, gn)
if ok && oldg.Equals(newg) {
groups[gn] = oldg
continue
}
wg.Add(1)
go func(newg *Group) {
if ok {
oldg.stop()
newg.CopyState(oldg)
}
go func() {
// 开始运行新的规则组
<-m.block
newg.run(m.opts.Context)
}()
wg.Done()
}(newg)
}
// 停止所有旧的组和规则
// 开始运行新的规则组
// 这里要阻塞,直到调用ruleManager.Start()方法后才可以继续执行
// 因为执行规则时要查询数据,但是查询数据的时候数据源可能还未准备好
// 因此要等数据源初始化并且上层调用Start方法后才可以继续执行
wg.Add(len(m.groups))
for n, oldg := range m.groups {
go func(n string, g *Group) {
g.markStale = true
g.stop()
if m := g.metrics; m != nil {
m.evalTotal.DeleteLabelValues(n)
m.evalFailures.DeleteLabelValues(n)
m.groupInterval.DeleteLabelValues(n)
m.groupLastEvalTime.DeleteLabelValues(n)
m.groupLastDuration.DeleteLabelValues(n)
m.groupRules.DeleteLabelValues(n)
}
wg.Done()
}(n, oldg)
}
wg.Wait()
m.groups = groups
return nil
}
这里加载配置的规则组没什么好说的,主要就是读取配置文件并且解析。下面具体看下newg.run(m.opts.Context),新规则的具体执行内容。
func (g *Group) run(ctx context.Context) {
// .....
iter := func() {
g.metrics.iterationsScheduled.Inc()
start := time.Now()
// 具体执行
g.Eval(ctx, evalTimestamp)
timeSinceStart := time.Since(start)
// 执行过程的数据统计
g.metrics.iterationDuration.Observe(timeSinceStart.Seconds())
g.setEvaluationDuration(timeSinceStart)
g.setEvaluationTimestamp(start)
}
// .....
// 下面定时循环执行规则
for {
select {
case <-g.done:
return
default:
select {
case <-g.done:
return
case <-tick.C:
missed := (time.Since(evalTimestamp) / g.interval) - 1
if missed > 0 {
g.metrics.iterationsMissed.Add(float64(missed))
g.metrics.iterationsScheduled.Add(float64(missed))
}
evalTimestamp = evalTimestamp.Add((missed + 1) * g.interval)
iter()
}
}
}
}
规则组的具体执行流程:
for i, rule := range g.rules {
// 遍历规则组中的所有规则,依次执行
func(i int, rule Rule) {
// .......
vector, err := rule.Eval(ctx, ts, g.opts.QueryFunc, g.opts.ExternalURL)
if err != nil {
// Canceled queries are intentional termination of queries. This normally
// happens on shutdown and thus we skip logging of any errors here.
if _, ok := err.(promql.ErrQueryCanceled); !ok {
level.Warn(g.logger).Log("msg", "Evaluating rule failed", "rule", rule, "err", err)
}
// .......
return
}
// 判断规则是否是alert规则,如果是则发送告警信息(具体是否真正发送由ar.sendAlerts中的逻辑判断)
if ar, ok := rule.(*AlertingRule); ok {
ar.sendAlerts(ctx, ts, g.opts.ResendDelay, g.interval, g.opts.NotifyFunc)
}
}
// ........
}
然后就是规则的具体执行了,我们这里先只看AlertingRule的流程。首先看下AlertingRule的结构:
// An AlertingRule generates alerts from its vector expression.
type AlertingRule struct {
// The name of the alert.
name string
// The vector expression from which to generate alerts.
vector parser.Expr
// The duration for which a labelset needs to persist in the expression
// output vector before an alert transitions from Pending to Firing state.
holdDuration time.Duration
// Extra labels to attach to the resulting alert sample vectors.
labels labels.Labels
// Non-identifying key/value pairs.
annotations labels.Labels
// External labels from the global config.
externalLabels map[string]string
// true if old state has been restored. We start persisting samples for ALERT_FOR_STATE
// only after the restoration.
restored bool
// Protects the below.
mtx sync.Mutex
// Time in seconds taken to evaluate rule.
evaluationDuration time.Duration
// Timestamp of last evaluation of rule.
evaluationTimestamp time.Time
// The health of the alerting rule.
health RuleHealth
// The last error seen by the alerting rule.
lastError error
// A map of alerts which are currently active (Pending or Firing), keyed by
// the fingerprint of the labelset they correspond to.
active map[uint64]*Alert
logger log.Logger
}
这里比较重要的就是active字段了,它保存了执行规则后需要进行告警的资源,具体是否告警还要执行一系列的逻辑来判断是否满足告警条件。具体执行的逻辑如下:
func (r *AlertingRule) Eval(ctx context.Context, ts time.Time, query QueryFunc, externalURL *url.URL) (promql.Vector, error) {
res, err := query(ctx, r.vector.String(), ts)
if err != nil {
r.SetHealth(HealthBad)
r.SetLastError(err)
return nil, err
}
// ......
}
这一步通过创建Manager时传入的QueryFunc函数执行规则配置中的expr表达式,然后得到返回的结果,这里的结果是满足表达式的指标的集合。
比如配置的规则为:
cpu_usage > 80
那么查出来的结果可能是
cpu_usage{instance="192.168.0.100"} 85
cpu_usage{instance="192.168.0.101"} 92
然后遍历查询到的结果,根据指标的标签生成一个hash值,然后判断这个hash值是否之前已经存在(即之前是否已经有相同的指标数据返回),如果是,则更新上次的value及annotations,如果不是,则创建一个新的alert并保存至该规则下的active alert列表中。
然后遍历规则的active alert列表,根据规则的持续时长配置、alert的上次触发时间、alert的当前状态、本次查询alert是否依然存在等信息来修改alert的状态。具体规则如下:
- 如果alert之前存在,但本次执行时不存在
- 状态是StatePending或者本次检查时间距离上次触发时间超过15分钟(15分钟为写死的常量),则将该alert从active列表中删除
- 状态不为StateInactive的alert修改为StateInactive
- 如果alert之前存在并且本次执行仍然存在
- alert的状态是StatePending并且本次检查距离上次触发时间超过配置的for持续时长,那么状态修改为StateFiring
- 其余情况修改alert的状态为StatePending
上面那一步只是修改了alert的状态,但是并没有真正执行发送告警操作。下面才是真正要执行告警操作:
// 判断规则是否是alert规则,如果是则发送告警信息(具体是否真正发送由ar.sendAlerts中的逻辑判断)
if ar, ok := rule.(*AlertingRule); ok {
ar.sendAlerts(ctx, ts, g.opts.ResendDelay, g.interval, g.opts.NotifyFunc)
}
// .......
func (r *AlertingRule) sendAlerts(ctx context.Context, ts time.Time, resendDelay time.Duration, interval time.Duration, notifyFunc NotifyFunc) {
alerts := []*Alert{}
r.ForEachActiveAlert(func(alert *Alert) {
if alert.needsSending(ts, resendDelay) {
alert.LastSentAt = ts
// Allow for two Eval or Alertmanager send failures.
delta := resendDelay
if interval > resendDelay {
delta = interval
}
alert.ValidUntil = ts.Add(4 * delta)
anew := *alert
alerts = append(alerts, &anew)
}
})
notifyFunc(ctx, r.vector.String(), alerts...)
}
func (a *Alert) needsSending(ts time.Time, resendDelay time.Duration) bool {
if a.State == StatePending {
return false
}
// if an alert has been resolved since the last send, resend it
if a.ResolvedAt.After(a.LastSentAt) {
return true
}
return a.LastSentAt.Add(resendDelay).Before(ts)
}
概括一下以上逻辑就是:
- 如果alert的状态是StatePending,则不发送告警
- 如果alert的已经被解决,那么再次发送告警标识该条信息已经被解决
- 如果当前时间距离上次发送告警的时间大于配置的重新发送延时时间(ResendDelay),则发送告警,否则不发送
以上大致介绍了从加载告警规则配置到最后执行告警的大致逻辑,后续会详细介绍具体的一些细节,敬请关注!
