本文是对一次数据迁移过程的详细记录。
背景
系统重构了以后,需要把老数据迁移至新系统,并且老系统仍然需要持续运行一段时间来进行过渡,期间的产生的数据也要保持同步。同时,由于业务原因,新系统产生的部分数据也要同步回老系统,这样才能保证老系统的正常运行。因此,业务需求总结下来就是以下三点:
- (前提条件)新老系统表结构完全不一样
- 老系统全部数据同步至新系统(全量同步)
- 老系统新产生的数据也要同步至新系统(增量同步)
- 新系统产生的部分数据也要同步至老系统(增量同步)
方案确定
全量同步其实没啥好说的,只能全部查出来然后一一进行导入。
最初确定增量同步方案时主要有两种:
- 方案一:hook老系统请求接口,在老系统收到请求时,将数据进行整合后导入新系统。
- 方案二:定时轮询数据库,有新增数据时进行同步。
方案一很快就被否定了,因此缺点实在太多了。1. 对原系统侵入性太大,需要改原系统的代码。2.请求接口和数据表不一定能一一对应,有的接口可能要修改多个表,有的时候多个接口修改同一个表。改造的时候比较复杂,心智负担较重。3.请求数据合法性要校验,校验通过时才允许同步,这样数据校验的代码就要重新再写一遍。4.可能会影响原来接口的响应时间。如果同步处理,那么一定会影响到响应时间,如果异步处理,则可能存在数据丢失的风险。如果通过消息队列进行处理,那前面三点问题仍然不能解决,并且额外增加系统复杂度。5.不好保证数据一致性,可能老系统数据成功插入,但是新系统插入失败,这种情况除了记日志没别的办法了。
方案二稍微靠谱点,但是也有问题。1. 需要记录同步的进度,以便程序挂了的时候能够从上次的进度继续处理。2.数据产生的频率不一致,不好确定轮询时间。有的表产生数据很频繁,需要频繁扫描,有的表几乎很少产生数据,如果频繁扫描则空转几率较大,比较浪费。3.新增数据很好发现,修改的数据比较难发现,需要所有表都有更新时间字段,并且数据更新时这两个字段也必须更新。
后来想到了方案三,几乎完美解决了上面的几个问题。
方案三:通过数据库的binlog进行同步。
Binlog是用来记录Mysql内部对数据库的改动(只记录对数据的修改操作),主要用于数据库的主从复制以及增量恢复。
最终确定了整体的迁移方案:全量同步+binlog增量同步
方案详情
确定了整体的迁移方案后,接下来是方案的一些细节。由于新老系统表结构并不一致,所以实际迁移还是有不少问题的。
全量同步
1. 横向迁移 vs 纵向迁移
全量同步首先要确定的问题就是按照业务模型进行迁移(横向) 还是 按照数据表(纵向) 进行迁移,这是两个不同的方向。按照业务模型迁移就是从业务主要模型入手,查询主要模型数据,然后依次查询模型对应的其他数据,然后迁移这个模型相关的所有数据。按照数据表迁移就是忽略业务模型,直接按照查询表中的数据,然后一一迁移,一个表的全部数据迁移完毕后,再迁移另外的表。
举个例子来说。学生管理系统,一个学生管理系统可能包括以下内容:

按照业务模型进行迁移则是如下图所示:
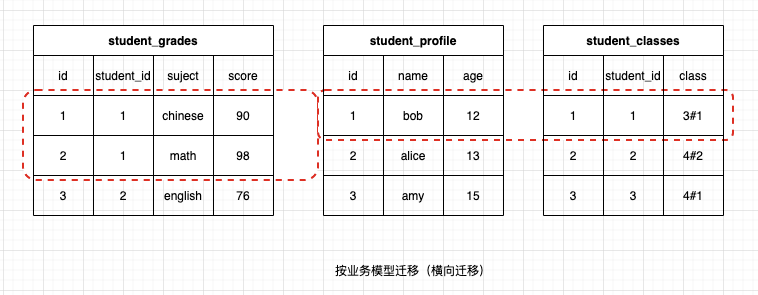
首先查询学生信息,然后查询这个学生关联的班级、成绩等信息,然后将这个学生的所有信息进行迁移,迁移完成后再对下一个同学的信息进行迁移。这种方式是对每个表的其中某一行或者某几行进行迁移,因此叫横向迁移。
按照数据表迁移是先将单个表的所有数据都迁移完毕后再迁移其他的表,因此叫纵向迁移。
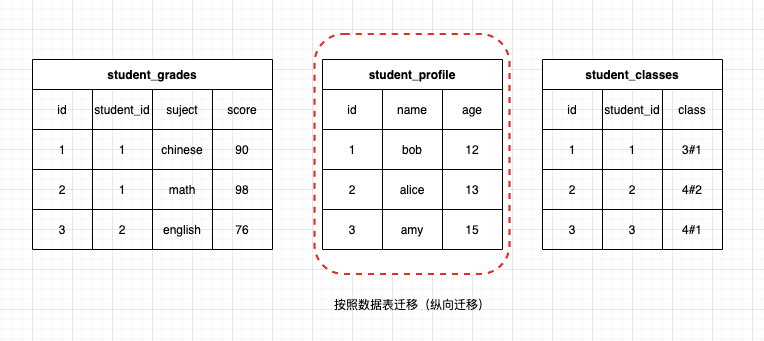
最终还是选择了按照数据表迁移,因为这样数据不容易有遗漏,而且迁移内容较为单一,更不容易出错。同时,在导入出错时更容易重试。
2. 数据如何进行对应?
遇到的第二个问题就是,数据该如何进行对应?
还以上面的学生管理系统为例,student_profile表中id为1的数据迁移至新系统之后,id是自增的,可能和原来的id不一致,那么在迁移student_classes表的时候,表里的student_id字段该如何获得?
其中一个解决方法就是迁移student_classes表的时候,先在老系统中查到对应的学生信息,然后根据这些信息再在新系统中查找到对应的id,然后在写入student_classes表中。但是这样做有两个问题:
- 每同步一条数据,都需要进行查询,甚至可能需要多次查询,效率太慢了。
- 如果数据缓存在内存中,那数据量比较大的表占用的内存太大,承受不了。
- 对数据表的导入顺序要求比较严格。如果需要查询的数据还未导入,那么肯定查询不到了。
造成这个问题的主要原因就是迁移之后id重新生成了,那如果保持原来的id不变,就不用担心这种问题了,也即导入的时候指定id而不是自动生成就好了。
但是又会遇到另外一个问题,系统重构一般伴随着更高级的抽象,将原来多个不同的模块抽象为更通用的概念,那么老系统的多个表的数据可能会迁移至新系统的同一个表中,这种情况怎么办?如下图:
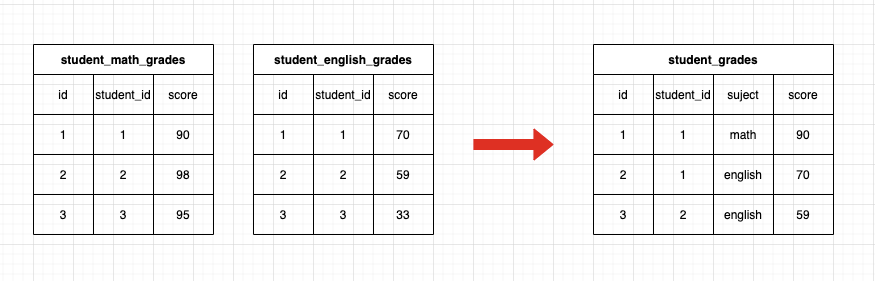
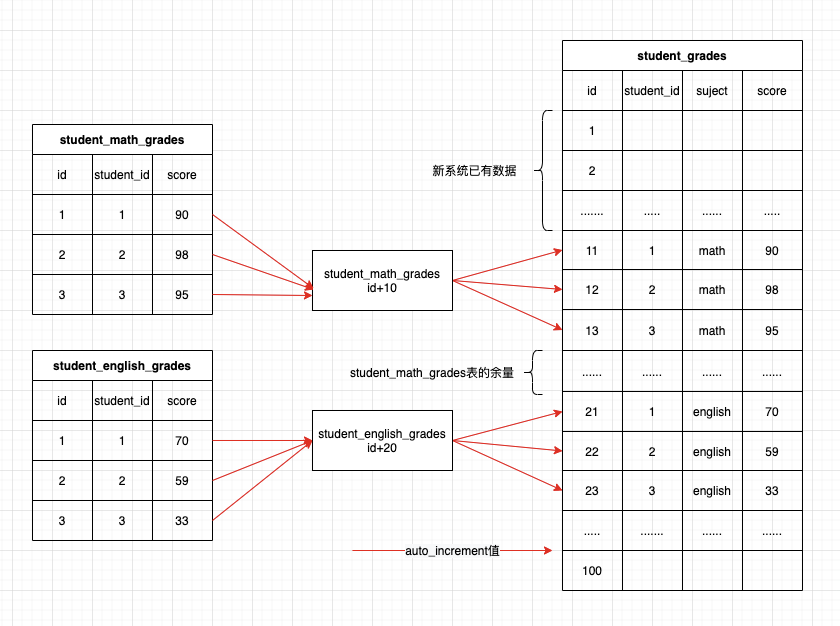
老表的id也都是从1开始自增的,并且自增步长均为1,如果保持id不变导入新系统,那id肯定会重复,这时候怎么办?
想到的解决办法就是为不同的表设置不同的id偏移量,从id从老系统转为新系统的id时加上不同的偏移量,这样就解决了id冲突的问题。
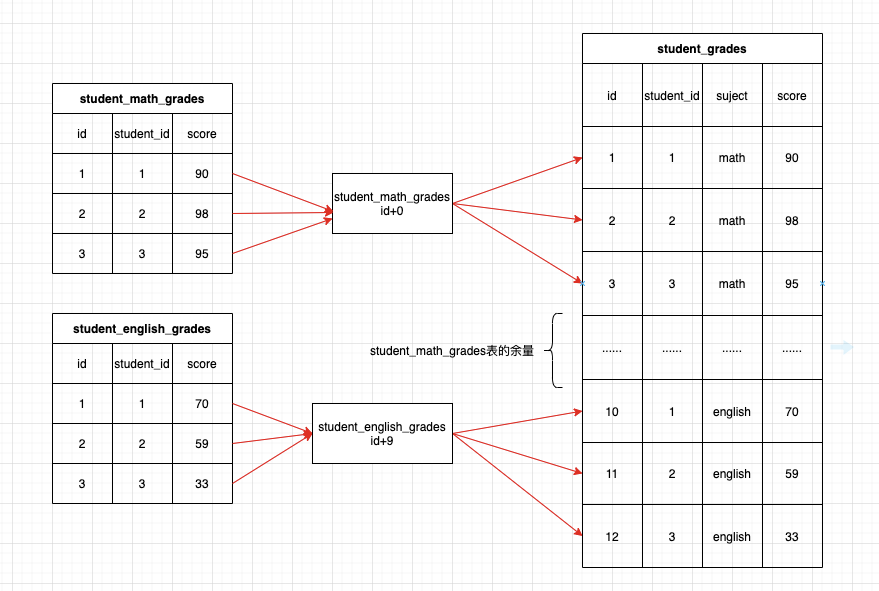
在设置偏移量的时候要注意,偏移量应当为数据表的id的最大值,而不是数据表的行数,因为数据表中可能会有数据删除。当然只有逻辑删除没有物理删除的情况下,两者应当是一致的。当然,偏移量仅仅是数据表id的最大值也是不够的,因为后续数据还会持续增加,增量同步的时候可能就会有重复的情况了,因此还要为后续可能增加的数据留一定的余量。
同时,还要考虑新系统本身已经有了部分数据的情况,这时候oldId+offset也还是可能有重复,这时可以再在以上的基础上增加一个基础偏移量,为了简单,可以为所有表设置一个一致的偏移量,当然,如果表数据量差别比较大的情况下,还是分别设置比较好。
可以提供一个公共的方法来生成id,如下:
const baseOffset = 10000
var idOffset = map[string]int64{
"student_math_grades": 0,
"student_english_grades": 9,
// .......
}
func ToNewId(tableName string, oldId int64) int64 {
if oldId == 0 {
return 0
}
offset, ok := idOffset[tableName]
if !ok { // 避免typo问题
panic("table offset not found: " + tableName)
}
return oldId + offset + baseOffset
}
增量同步
增量同步的问题较少,需要注意的一点是binlog格式需要设置为row格式,这样才能获得每一行数据变更的详情。
1. 循环同步问题
前面说过,新系统的部分数据也需要同步回老系统,那么随之而来的就是循环同步的问题。比如说老系统同步了一条数据至新系统,这时候binlog监听到新系统有数据增加,那么这条数据会被同步回老系统,然后老系统再同步至新系统……如此循环往复直至系统爆炸。
解决方案也比较简单,在新系统中的表中增加from_old字段,标识该条数据是否是从老系统同步过来的,同时在老系统中也增加from_new字段,标识数据是否从新系统同步来的。在增量同步时,首先判断from_old或者from_new字段,如果为true,则说明本条数据是同步过来的,不再同步回老(新)系统,这样就打破了循环。
2. 数据覆盖问题
考虑以下情况:
- 若offset=10000,老系统的最新一条数据id为1234,则同步至新系统后id为11234。
- 新系统中创建了一条数据,id自增,为11235。
- 老系统中也创建了一条数据,id自增,为1235。
- 老系统中的数据同步至新系统,过来的id为1235+10000=11235,和新系统中创建的数据id重复了。
为了防止以上情况的发生,需要为会从老系统同步数据的数据表重新设置auto_increment值。新的auto_increment值为老系统同步过来的数据的id最大值加上预留的余量,最终如下图所示:
总结
这个项目花了不少的时间,中间遇到的问题还是不少的,繁琐细节太多了,事后梳理一下还是清晰了不少。
对方案有任何意见的或者有更好的方案的,欢迎随时讨论。
